728x90
반응형
SMALL
Routing in Packet Switching Networks
패킷 교환 네트워크의 주요 기능은 소스 스테이션으로부터 패킷을 받아서 목적지 스테이션으로 전달하는 것, 이를 위해 네트워크를 통한 경로가 결정되어야 하며 일반적으로 하나 이상의 경로가 가능합니다.
라우팅 결정은 결정 시점과 결정 위치에 따라 구분됩니다:
결정 시점:
패킷 단위: 데이터그램 방식에서는 각 패킷마다 개별적으로 라우팅 결정
가상 회선 단위: 가상 회선 설정 시점에 라우팅 결정, 이후 동일 경로 사용
동적 변경 가능 (네트워크 과부하나 장애 대응)
결정 위치:
분산 라우팅: 각 노드가 도착한 패킷의 출력 링크를 선택
중앙집중 라우팅: 네트워크 제어 센터가 모든 라우팅 결정. (센터 장애 시 네트워크 운영 차단 위험 있음)
출발지 라우팅: 출발지 스테이션에서 라우팅 결정 후 네트워크에 전달. (사용자가 경로 지정 가능)
Routing Strategies - Fixed Routing
고정 경로 라우팅(Fixed Routing)은 각 소스-목적지 노드 쌍에 대해 하나의 영구 경로를 설정하는 기법으로, 일반적으로 최소 비용 알고리즘을 사용하여 경로를 결정합니다. 설정된 경로는 네트워크 토폴로지가 변경되기 전까지 고정되며, 예상되는 트래픽 양이나 네트워크 용량을 기반으로 설계됩니다.
이 방식은 구현이 단순하고 안정적인 네트워크 환경에서 효과적입니다. 그러나 고정된 경로를 사용하기 때문에 네트워크 혼잡이나 장애 상황에 대응하지 못하는 유연성 부족이 주요 단점으로 꼽힙니다. 따라서 고정 경로 라우팅은 안정성과 단순성이 요구되는 환경에서는 적합하지만, 동적인 네트워크 상황에서는 비효율적일 수 있습니다.
Routing Strategies: Flooding
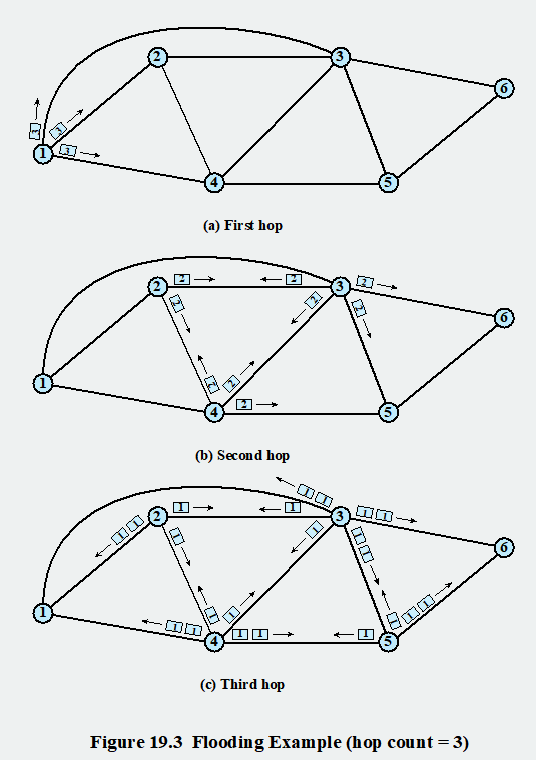
Flooding은 네트워크 정보 없이 작동하는 단순한 라우팅 기법으로, 소스 노드가 패킷을 모든 인접 노드로 전송하며, 각 노드도 받은 패킷을 다른 모든 출력 링크로 재전송합니다. 이를 통해 여러 복사본이 목적지에 도달합니다. 중복 처리를 방지하기 위해 패킷에 고유 식별자를 포함하거나 홉 카운트를 설정합니다. 홉 카운트는 패킷의 이동 범위를 제한하며, 0에 도달하면 패킷을 폐기합니다.
Routing Strategies: Random Routing
랜덤 라우팅은 플러딩의 단순성과 견고함을 유지하면서도 트래픽 부하를 줄인 기법입니다. 노드는 수신된 패킷을 재전송하기 위해 하나의 출력 경로를 무작위로 선택하며, 도착한 링크를 제외한 출력 링크 중 하나를 이용하거나 라운드 로빈 방식으로 전송할 수 있습니다.
개선된 방식으로는 출력 링크에 확률을 할당해 데이터 전송률이나 링크 비용을 기반으로 경로를 선택할 수 있습니다. 네트워크 정보가 필요하지 않아 구현이 간단하지만, 경로가 랜덤으로 선택되기 때문에 최소 비용 경로나 최소 홉 경로가 보장되지 않습니다.
Routing Strategies: Adaptive Routing
적응형 라우팅은 네트워크 상태에 따라 라우팅 결정을 동적으로 변경하는 기법으로, 장애와 혼잡 같은 조건에 대응합니다. 장애 발생 시 고장 난 경로를 우회하며, 네트워크 혼잡이 심한 구간은 회피하도록 설계됩니다. 이를 위해 노드 간 상태 정보를 교환하며 네트워크 상황에 따라 경로를 최적화합니다.
적응형 라우팅은 동적 환경에서 유용하지만, 효율성을 위해 정보 교환과 반응 속도를 적절히 조정해야 합니다.

{적응형 라우팅 전략의 분류}
1. 로컬 (Local, Isolated)
- 가장 짧은 대기열을 가진 출력 링크로 라우팅.
- 각 목적지에 대한 편향(bias)을 포함할 수 있음.
- 사용 가능한 정보를 활용하지 않기 때문에 거의 사용되지 않음.
2. 인접 노드 (Adjacent Nodes)
- 지연 및 장애 정보 활용.
- 분산 또는 중앙 집중화 방식으로 적용 가능.
3. 모든 노드 (All Nodes)
- 인접 노드 방식과 유사하나, 네트워크의 모든 노드 정보를 활용.
Internet Routing Protocols
라우터는 네트워크를 연결하는 시스템에서 패킷을 수신하고 전달하는 역할을 수행하며, 인터넷의 토폴로지와 트래픽/지연 상태에 대한 정보를 기반으로 라우팅 결정을 내립니다. 이를 위해 라우터는 특정 라우팅 프로토콜을 사용하여 라우팅 정보를 교환합니다.
라우팅 기능을 고려할 때 두 가지 주요 개념이 있습니다.
1. 라우팅 정보: 인터넷의 토폴로지와 지연에 대한 정보.
2. 라우팅 알고리즘: 현재 라우팅 정보를 기반으로 특정 데이터그램의 경로를 결정하는 알고리즘
=> 이러한 시스템은 효율적인 데이터 전달과 네트워크 상태에 따라 최적의 경로를 선택하기 위해 설계되었습니다.
Dijkstra’s Algorithm
다익스트라 알고리즘은 그래프에서 소스 노드에서 다른 모든 노드까지의 최단 경로를 찾는 알고리즘입니다
문제 1: 다익스트라 알고리즘
문제:
다익스트라 알고리즘은 소스 노드에서 다른 모든 노드로의 최단 경로를 계산하는 데 사용됩니다. 다익스트라 알고리즘의 작동 과정을 다음 단계를 포함하여 서술하시오.
- 초기화 단계
- 최단 경로를 선택하는 과정
- 경로 비용 갱신 방법
또한, 다익스트라 알고리즘이 음수 가중치를 처리할 수 없는 이유를 설명하시오.
답안:
- 초기화 단계: 소스 노드의 거리를 0으로 설정하고, 다른 노드들의 거리를 무한대로 설정합니다. 소스 노드를 포함하는 집합 T를 초기화합니다.
- 최단 경로 선택: T에 포함되지 않은 노드 중 가장 작은 경로 비용을 가진 노드를 선택하여 T에 추가합니다.
- 경로 비용 갱신: 새로 추가된 노드를 기준으로 인접한 노드들의 경로 비용을 갱신합니다. 기존 비용과 새 경로 비용 중 더 작은 값을 선택합니다.
- 음수 가중치 처리 불가 이유: 다익스트라 알고리즘은 각 단계에서 현재 최단 경로를 확정짓는 그리디 방식으로 작동합니다. 음수 가중치가 있을 경우, 이후에 더 작은 비용의 경로가 발견될 가능성이 있어 정확하지 않은 결과를 낼 수 있습니다
Bellman Ford Algorithm
Bellman-Ford 알고리즘은 주어진 소스 노드에서 다른 모든 노드로의 최단 경로를 찾는 알고리즘입니다. 초기에는 경로가 최대 하나의 링크를 포함하도록 설정하며, 이후 각 반복 단계에서 경로 길이를 하나씩 증가시키며 최단 경로를 갱신합니다. 각 단계에서 목적지 노드에 대해 이전 단계에서 계산된 경로와 새로운 링크를 추가한 경로를 비교하여 비용이 더 작은 경로를 선택합니다. 이렇게 경로 길이가 최대 K+1링크일 때까지 반복하며, 각 반복은 이전 단계의 결과를 기반으로 진행됩니다. Bellman-Ford는 음수 가중치를 허용하며 점진적으로 경로를 계산합니다.
문제 2: 벨만-포드 알고리즘
문제:
벨만-포드 알고리즘은 소스 노드에서 모든 노드로의 최단 경로를 찾는 데 사용됩니다. 알고리즘의 주요 반복 과정을 설명하고, 벨만-포드 알고리즘이 다익스트라 알고리즘과 달리 음수 가중치를 처리할 수 있는 이유를 기술하시오.
답안:
- 반복 과정:
- 초기화 단계에서 모든 노드의 경로 비용을 무한대로 설정하며, 소스 노드의 경로 비용을 0으로 설정합니다.
- 이후 모든 간선을 최대 V−1번 반복하며 갱신합니다. 각 반복에서 각 간선을 확인하여, 만약 간선을 따라 이동한 비용이 기존 경로 비용보다 작으면 갱신합니다.
- 음수 가중치 처리 가능 이유:
- 벨만-포드 알고리즘은 모든 간선을 반복적으로 확인하여 최단 경로를 갱신하므로 음수 가중치가 포함된 그래프에서도 정확한 최단 경로를 계산할 수 있습니다.
- 음수 사이클 확인:
- 마지막 반복 이후에도 경로 비용이 더 작아지는 경우, 음수 사이클이 존재함을 확인할 수 있습니다. 이는 다익스트라 알고리즘으로는 불가능합니다.
728x90
반응형
LIST
'Computer Science > 데이터 통신' 카테고리의 다른 글
| Chapter 14. 인터넷 프로토콜 (0) | 2024.12.06 |
|---|---|
| Chapter 11. 로컬 영역 네트워크(LAN) (0) | 2024.12.01 |
| Chapter 10. 셀룰러 무선 네트워크 (2) | 2024.12.01 |
| Chapter 09. WAN 기술과 프로토콜 (0) | 2024.11.23 |
| Chapter 08. 멀티플렉싱 (0) | 2024.11.23 |